DOAG Conference 2019 Presentation: “LINUX Know-How for DBAs (german)”
By Martin | November 20th, 2019 | Category: Uncategorized | No Comments »I have uploaded my presentation plus the recorded demos to the website.

I have uploaded my presentation plus the recorded demos to the website.
After applying Oracle Database Proactive Bundle Patch (DBBP) 12.1.0.2 April 2018 (Patch 27486326), the datapump dump file internal format is changed from version 4.1 to version 4.2. The effect is, that a dump file created with DataPump from Version 12.1.0.2 DBBP 180417 can no longer be imported in any lower database except when the datapump export is performed with VERSION=12.1 clause.
MOS 462488.1 gives a script to extract Dump File Version from file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | SQL> exec show_dumpfile_info('DATA_PUMP_DIR','test.dmp'); ---------------------------------------------------------------------------- Purpose..: Obtain details about export dumpfile. Version: 18-DEC-2013 Required.: RDBMS version: 10.2.0.1.0 or higher . Export dumpfile version: 7.3.4.0.0 or higher . Export Data Pump dumpfile version: 10.1.0.1.0 or higher Usage....: execute show_dumfile_info('DIRECTORY', 'DUMPFILE'); Example..: exec show_dumfile_info('MY_DIR', 'expdp_s.dmp') ---------------------------------------------------------------------------- Filename.: test.dmp Directory: DATA_PUMP_DIR Disk Path: ... Filetype.: 1 (Export Data Pump dumpfile) ---------------------------------------------------------------------------- ...Database Job Version..........: 12.01.00.02.00 ...Internal Dump File Version....: 4.2 ...Creation Date.................: Tue Jun 05 16:23:31 2018 ...File Number (in dump file set): 1 ...Master Present in dump file...: 1 (Yes) ...Master in how many dump files.: 1 ...Master Piece Number in file...: 1 ...Operating System of source db.: x86_64/Linux 2.4.xx ...Instance Name of source db....: myhost:MYINST ...Characterset ID of source db..: 178 (WE8MSWIN1252) ...Language Name of characterset.: WE8MSWIN1252 ...Job Name......................: "MYUSER"."SYS_EXPORT_FULL_01" ...GUID (unique job identifier)..: 6DE6CAA3E6377A30E053A505120A8FB1 ...Block size dump file (bytes)..: 4096 ...Metadata Compressed...........: 1 (Yes) ...Data Compressed...............: 0 (No) ...Compression Algorithm.........: 3 (Basic) ...Metadata Encrypted............: 0 (No) ...Table Data Encrypted..........: 0 (No) ...Column Data Encrypted.........: 0 (No) ...Encryption Mode...............: 2 (None) ...Internal Flag Values..........: 514 ...Max Items Code (Info Items)...: 23 ---------------------------------------------------------------------------- PL/SQL procedure successfully completed. |
When trying to import dump in lower version database, this error is raised:
1 2 3 | ORA-39001: invalid argument value ORA-39000: bad dump file specification ORA-39142: incompatible version number 4.2 in dump file "test.dmp" |
Only workaround is to use option “VERSION=12.1” when performing the datapump export.
Update 14.06.2018: Oracle Support has published a MOS Note for this issue today: 2409523.1
Update 16.07.2018: A month after we had experienced the issue, oracle has published an “Alert” in MOS this MOS Note: Alert – Regression in DataPump After Applying 12.1.0.2.180417DBBP or 12.1.0.2.180717DBBP (Doc ID 2422236.1)
In addition, a patch is now available: 21480031
I recently had to troubleshoot a hung instance in a 2 node RAC system. 4 months earlier, the system was reinstalled in a rolling fashion due to the requirement of Linux Upgrade from Oracle Linux 5 to Oracle Linux 7. This was required because of lack of certification for a storage migration to an AllFlash Storage. The system has been stable when running with Oracle Linux 5 for several years. Around 4 months after the reinstallation, one node got hung with and traces showed these error messages:
1 2 3 4 5 6 7 8 9 | Mon Feb 26 08:53:37 2018 skgxpvfynet: mtype: 61 process 15801 failed because of a resource problem in the OS. The OS has most likely run out of buffers (rval: 4) Errors in file /u01/app/oracle/diag_p/diag/rdbms/prod/PROD2/trace/PROD2_ora_15801.trc (incident=480004): ORA-00603: ORACLE server session terminated by fatal error ORA-27504: IPC error creating OSD context ORA-27300: OS system dependent operation:sendmsg failed with status: 105 ORA-27301: OS failure message: No buffer space available ORA-27302: failure occurred at: sskgxpsnd2 Incident details in: /u01/app/oracle/diag_p/diag/rdbms/prod/PROD2/incident/incdir_480004/PROD2_ora_15801_i480004.trc |
This was strange because OS /proc/meminfo was showing huge amounts of free memory for this physical host with 512GB of RAM.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | [root@node17 ~]# cat /proc/meminfo zzz ***Mon Feb 26 08:53:09 CET 2018 MemTotal: 528028424 kB MemFree: 14593828 kB MemAvailable: 78305772 kB Buffers: 28009752 kB Cached: 46896496 kB SwapCached: 0 kB Active: 22627436 kB Inactive: 66945168 kB Active(anon): 14315300 kB Inactive(anon): 2105748 kB Active(file): 8312136 kB Inactive(file): 64839420 kB Unevictable: 363996 kB Mlocked: 364020 kB SwapTotal: 33554428 kB SwapFree: 33554428 kB Dirty: 404 kB Writeback: 0 kB AnonPages: 15768480 kB Mapped: 709896 kB Shmem: 945384 kB Slab: 2462644 kB SReclaimable: 2092232 kB SUnreclaim: 370412 kB KernelStack: 28336 kB PageTables: 395568 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 87853440 kB Committed_AS: 22087384 kB VmallocTotal: 34359738367 kB VmallocUsed: 1106260 kB VmallocChunk: 34085810172 kB HardwareCorrupted: 0 kB AnonHugePages: 0 kB CmaTotal: 16384 kB CmaFree: 0 kB HugePages_Total: 204800 HugePages_Free: 20214 HugePages_Rsvd: 6266 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 36827756 kB DirectMap2M: 78444544 kB DirectMap1G: 423624704 kB |
Oracle Support then referred to this MOS Note:
ORA-27301: OS Failure Message: No Buffer Space Available / ORA-27302: failure occurred at: sskgxpsnd2 ( Doc ID 2322410.1 )
It turned out that on systems with a lot of physical memory and on Oracle Linux 7, the MTU size of loopback adapter lo0 has to be reduced from the default value of 64k to 16436 bytes to avoid memory fragmentation in RAC. The note also mentioned that the parameter vm.min_free_kbytes should be set to physmem * 0,004 *
I was very surprised that neither Cluster Verification Utility (CVU), nor orachk in most recent version did catch this problem at the point of installation. In my opinion, if default value of MTU size of loopback interface on Oracle Linux 7 has the potential to cause an outage, then this must be pre-checked by CVU at installation time or at least integrated into orachk. Unfortunately, this is not the case. It seems that in July we will know if the on-prem release 18.3.0 eventually will catch and enforce this configuration requirement during installation time.
During my consulting engagements I see a lot of systems and many bugs. Most of the time, there is already a patch available to avoid the bug. I have collected all the recommended patches for the Oracle Database 12.1.0.2 (SE2 and EE) and Oracle Enterprise Manager 13cR2. This should help to avoid most critical known issues. Versions 12.2.0.1 and 18c will be added later this year.
Update: 18.05.2018: I have added a list of recommended patches for release 12.2.0.1.
Update: 17.07.2018: Updated EM 13.2 Patches
If you are managing volatile systems, you might have encountered Archiver-Stuck in the past.
1 2 | 0RA-00257:archiver error, connect internal only until freed ORA-16014:log 2 sequence# 1789 not archived, no available destinations |
If this is the case, you might be interested in a rarely used feature called “ALTERNATE Archive Locations”. This is a second independent archive log destination, that is only used in case the primary destination is failing (full). In that case, the dest_2 is automatically enabled, preventing stuck database. As soon as the archivelog backup has cleaned up the full DEST_1 destination, there is an AUTOMATIC FALLBACK to the DEST_1 destination.
1 2 3 4 | ALTER SYSTEM SET LOG_ARCHIVE_DEST_1='LOCATION=/disk1 MANDATORY MAX_FAILURE=1 ALTERNATE=LOG_ARCHIVE_DEST_2'; ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1=ENABLE; ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2=ALTERNATE; ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='LOCATION=/disk2 MANDATORY ALTERNATE=LOG_ARCHIVE_DEST_1'; |
Testing:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | Thread 1 advanced to log sequence 174 (LGWR switch) Current log# 3 seq# 174 mem# 0: /u01/app/oracle/oradata/CDB122/redo03.log 2018-04-27T17:18:47.685736+02:00 ARC3: Encountered disk I/O error 19502 2018-04-27T17:18:47.685800+02:00 ARC3: Closing local archive destination LOG_ARCHIVE_DEST_1 '/disk1/1_173_971869447.dbf' (error 19502) (CDB122) 2018-04-27T17:18:47.687074+02:00 Errors in file /u01/app/oracle/diag/rdbms/cdb122/CDB122/trace/CDB122_arc3_31260.trc: ORA-27072: File I/O error Additional information: 4 Additional information: 65536 Additional information: 315392 ORA-19502: write error on file "/disk1/1_173_971869447.dbf", block number 65536 (block size=512) 2018-04-27T17:18:47.816938+02:00 Errors in file /u01/app/oracle/diag/rdbms/cdb122/CDB122/trace/CDB122_arc3_31260.trc: ORA-19502: write error on file "/disk1/1_173_971869447.dbf", block number 65536 (block size=512) ORA-27072: File I/O error Additional information: 4 Additional information: 65536 Additional information: 315392 ORA-19502: write error on file "/disk1/1_173_971869447.dbf", block number 65536 (block size=512) ARC3: I/O error 19502 archiving log 2 to '/disk1/1_173_971869447.dbf' |
After the error, archivelogs are placed in /dir2 directory and as soon as space is available again, archive destination is switched back to /dir1 automatically.
Archiver Stuck never again, right?
I recently troubleshooted an issue with RMAN catalog database using seperate schemas for each target database and more than 300 schemas present. Catalog Database was on 12.2.0.1 and suffering from severe mutex contention because of huge version counts for RMAN catalog SQL statements. I then realized that the default number of max child cursors was increased from 1024 to 8192 in 12.2.0.1. This made me check what other parameters were changed. In my opinion, especially interesting are parameters, that were OFF / FALSE in 12.1.0.2 and ON / TRUE in 12.2.0.1 as this probably activates new code.
This SQL Statement shows all parameters, including hidden parameters:
1 2 3 4 5 6 7 8 9 | -- file pd2.sql SET LINES 3000 pages 0 feedback off trimspool ON SELECT n.ksppinm ||'|'|| c.ksppstvl ||'|'|| n.ksppdesc FROM sys.x$ksppi n, sys.x$ksppcv c WHERE n.indx=c.indx ; |
Then, I spooled Pipe-seperated output to text files for both releases:
1 2 3 4 5 6 7 8 9 10 11 | . ~/121.env sqlplus / as sysdba <<EOF spool /tmp/121.txt @/tmp/pd2.sql EOF . ~/122.env sqlplus / as sysdba <<EOF spool /tmp/122.txt @/tmp/pd2.sql EOF |
Finally, I set up External Tables for accessing these files with SQL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | sqlplus / as sysdba
drop table db122 purge;
drop table db121 purge;
CREATE TABLE db122 (
param VARCHAR2(2000),
param_val VARCHAR2(2000),
param_desc VARCHAR2(2000)
)
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY tmp_dir
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY '|'
MISSING FIELD VALUES ARE NULL
(
param CHAR(2000) ,
param_val CHAR(2000),
param_desc CHAR(2000)
)
)
LOCATION ('122.txt')
)
PARALLEL 1
REJECT LIMIT UNLIMITED;
CREATE TABLE db121 (
param VARCHAR2(2000),
param_val VARCHAR2(2000),
param_desc VARCHAR2(2000)
)
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY tmp_dir
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY '|'
MISSING FIELD VALUES ARE NULL
(
param CHAR(2000) ,
param_val CHAR(2000),
param_desc CHAR(2000)
)
)
LOCATION ('121.txt')
)
PARALLEL 1
REJECT LIMIT UNLIMITED; |
The final query now compares hidden parameters:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 | SET LINES 500 pages 2000 tab off col param format a56 col db121_value format a20 col db122_value format a20 col param_desc heading DESCRIPTION format a100 word_wrap SELECT db121.param, db121.param_val AS db121_value, db122.param_val AS db122_value, db122.param_desc FROM (SELECT param, param_val, param_desc FROM db121) db121, (SELECT param, param_val, param_desc FROM db122) db122 WHERE db121.param = db122.param AND db121.param_val != db122.param_val AND db121.param LIKE '\_%' escape '\' and db121.param not IN ( '__db_cache_size', '__pga_aggregate_target', '__pga_aggregate_target', '__shared_pool_size', '__streams_pool_size', '_diag_adr_trace_dest', '__large_pool_size') order by db121.param; PARAM DB121_VALUE DB122_VALUE DESCRIPTION -------------------------------------------------------- -------------------- -------------------- ---------------------------------------------------------------------------------------------------- _adaptive_scalable_log_writer_disable_worker_threshold 90 50 Percentage of overlap across multiple outstanding writes _advanced_index_compression_options_value 20 0 advanced index compression options2 _aq_latency_absolute_threshold 100 300 Absolute threshold greater than average latency _aq_latency_relative_threshold 30 100 Relative threshold of average latency _aq_lb_stats_collect_cycle 120 45 Time(seconds) between consecutive AQ load statistics collection _aq_lookback_size 30 60 AQ PT Look Back Size _aq_pt_shrink_frequency 30 1450 PT shrink window Size _aq_pt_statistics_window 30 60 PT statistics sample window Size _asm_compatibility 10.1 11.2.0.2 default ASM compatibility level _asm_max_cod_strides 5 10 maximum number of COD strides _asm_scrub_unmatched_dba 3 1024 Scrub maximum number of blocks with unmatched DBA _asm_xrov_nvios 4 8 Specify number of VIO processes _asm_xrov_single TRUE FALSE Enable single issues of IOs _bigdata_external_table FALSE TRUE enables use of ORACLE_HIVE and ORACLE_HDFS access drivers _cache_fusion_pipelined_updates FALSE TRUE Block ping without wait for log force _catalog_foreign_restore TRUE FALSE catalog foreign file restore _column_tracking_level 1 21 column usage tracking _compression_compatibility 12.1.0.2.0 12.2.0 Compression compatibility _controlfile_enqueue_holding_time_tracking_size 10 0 control file enqueue holding time tracking size _cursor_db_buffers_pinned 1387 1375 additional number of buffers a cursor can pin at once _cursor_obsolete_threshold 1024 8192 Number of cursors per parent before obsoletion. _db_block_buffers 444542 440775 Number of database blocks cached in memory: hidden parameter _db_block_cache_protect FALSE false protect database blocks (for debugging only) _dbg_scan 0 2048 generic scan debug _dbrm_dynamic_threshold 33490396 989922280 DBRM dynamic threshold setting _dbrm_runchk 0 32769000 Resource Manager Diagnostic Running Thread Check _dbwr_stall_write_detection_interval 0 900 dbwriter stall write detection interval _enable_pdb_close_abort FALSE TRUE Enable PDB shutdown abort (close abort) _gc_async_send FALSE TRUE if TRUE, send blocks asynchronously _gc_element_percent 120 105 global cache element percent _gc_latches 8 32 number of latches per LMS process _gc_max_downcvt 256 1024 maximum downconverts to process at one time _gc_msgq_buffers 128 0 set number of MSGQ buffers _gc_policy_time 10 20 how often to make object policy decisions in minutes _gc_trace_freelist_empty TRUE FALSE if TRUE, dump a trace when we run out of lock elements _gc_transfer_ratio 2 75 dynamic object read-mostly transfer ratio _gcs_latches 0 128 number of gcs resource hash latches to be allocated per LMS process _hang_base_file_space_limit 20000000 100000000 File space limit for current normal base trace file _hang_int_spare2 FALSE 0 Hang Management int 2 _hang_lws_file_space_limit 20000000 100000000 File space limit for current long waiting session trace file _hang_resolution_scope PROCESS OFF Hang Management hang resolution scope _hang_terminate_session_replay_enabled FALSE TRUE Hang Management terminates sessions allowing replay _ilmstat_memlimit 10 5 Percentage of shared pool for use by ILM Statistics _inmemory_fs_blk_inv_blk_percent 20 50 in-memory faststart CU invalidation threshold(blocks) _inmemory_fs_enable FALSE TRUE in-memory faststart enable _inmemory_imcu_target_rows 1048576 0 IMCU target number of rows _inmemory_private_journal_maxexts 32000 5000 Max number of extents per PJ _inmemory_private_journal_sharedpool_quota 64 20 quota for transaction in-memory objects _inmemory_repopulate_invalidate_rate_percent 100 0 In-memory repopulate invalidate rate percent _inmemory_repopulate_threshold_scans 2048 0 In-memory repopulate threshold number of scans _inmemory_strdlxid_timeout 327680 0 max time to determine straddling transactions _ipddb_enable TRUE FALSE Enable IPD/DB data collection _kebm_suspension_time 82800 104400 kebm auto suspension time in seconds _kgh_restricted_subheaps 60 180 number of subheaps in heap restricted mode _kgl_message_locks 64 256 RAC message lock count _kqr_optimistic_reads FALSE TRUE optimistic reading of row cache objects _kse_snap_ring_suppress 608 1403 6510 942 1403 List of error numbers to suppress in the snap error history _ksi_clientlocks_enabled TRUE FALSE if TRUE, DLM-clients can provide the lock memory _ksxp_ipclw_enabled 0 1 enable ipclw for KSXP _ktb_debug_flags 0 8 ktb-layer debug flags _lm_comm_channel ksxp msgq GES communication channel type _lm_comm_tkts_calc_period_length 5 1000 Weighted average calculation interval length (us) _lm_drm_min_interval 300 600 minimum interval in secs between two consecutive drms _lm_drmopt12 26 56 enable drm scan optimizations in 12 _lm_enable_aff_benefit_stats TRUE FALSE enables affinity benefit computations if TRUE _lm_procs 320 1088 number of client processes configured for cluster database _lm_xids 352 1196 number of transaction IDs configured for cluster database _lock_next_constraint_count 120 3 max number of attempts to lock _NEXT_CONSTRAINT _lthread_cleanup_intv_secs 5 1 interval for cleaning lightweight threads in secs _max_fsu_segments 4096 1024 Maximum segments to track for fast space usage _max_services 1024 8200 maximum number of database services _multi_instance_pmr FALSE TRUE enable multi instance redo apply _multiple_char_set_cdb FALSE TRUE Multiple character sets enabled in CDB _number_cached_group_memberships 32 2048 maximum number of cached group memberships _number_group_memberships_per_cache_line 3 6 maximum number of group memberships per cache line _optimizer_ads_use_partial_results FALSE TRUE Use partial results of ADS queries _optimizer_dsdir_usage_control 126 0 controls optimizer usage of dynamic sampling directives _optimizer_undo_cost_change 12.1.0.2 12.2.0.1 optimizer undo cost change _parallel_server_sleep_time 10 1 sleep time between dequeue timeouts (in 1/100ths) _pmon_dead_blkrs_max_blkrs 200 50 max blockers to check during cleanup _posix_spawn_enabled FALSE TRUE posix_spawn enabled _rcfg_parallel_verify TRUE FALSE if TRUE enables parallel verify at reconfiguration _reliable_block_sends TRUE FALSE if TRUE, no side channel on reliable interconnect _rowsets_max_rows 200 256 maximum number of rows in a rowset _side_channel_batch_size 200 240 number of messages to batch in a side channel message (DFS) _skip_trstamp_check FALSE TRUE Skip terminal recovery stamp check _small_table_threshold 8890 8815 lower threshold level of table size for direct reads _sql_plan_directive_mgmt_control 3 67 controls internal SQL Plan Directive management activities _step_down_limit_in_pct 1 20 step down limit in percentage _target_log_write_size_timeout 1 0 How long LGWR will wait for redo to accumulate (msecs) 90 rows selected. |
I had to troubleshoot an issue on a company ERP systems database, where several sessions were waiting for ‘enq: TX row lock contention’. It was a table containing print server nodes and this caused no more printouts. Usually troubleshooting locking issues is quite straightforward in recent versions of oracle database, but this time, the column “v$session.blocking_session” was not populated and there was no entry in v$lock for the blocker. This was strange, so I involved Oracle Support. They requested a system state dump.
SQL> oradebug setmypid
SQL> oradebug unlimit;
SQL> select * from dual;
SQL> oradebug dump systemstate 258
SQL> oradebug dump systemstate 258
In the system state dump, there was a reference for the hanging session:
Waiter:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | ----------------------------------------
SO: 0x000000075C68F8B8, type: 2, owner: 0x0000000000000000, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x000000075C68F8B8, name=process, file=ksu.h LINE:12740, pg=0
(process) Oracle pid:161, ser:247, calls cur/top: 0x000000075BC6A370/0x000000075BC6A370
flags : (0x0) -
flags2: (0x0), flags3: (0x10)
intr error: 0, call error: 0, sess error: 0, txn error 0
intr queue: empty
ksudlp FALSE at location: 0
(post info) last post received: 0 0 0
last post received-location: No post
last process to post me: none
last post sent: 0 0 0
last post sent-location: No post
last process posted by me: none
(latch info) wait_event=0 bits=0x0
Process Group: DEFAULT, pseudo proc: 0x000000076068CE68
O/S info: user: SYSTEM, term: HOSTNAME, ospid: 4600
OSD pid info: Windows thread id: 4600, image: ORACLE.EXE (SHAD)
Short stack dump:
ksedsts()+585<-ksdxfstk()+44<-ksdxcb()+2402<-ssthreadsrgruncallback()+629<-OracleOradebugThreadStart()+829
<-0000000076D559CD<-0000000076E8A561<-0000000076EABD7A<-000007FEFCE910AC<-skgpwwait()+182<-ksliwat()+2459
<-kslwaitctx()+184<-ksqcmi()+7848<-ksqgtlctx()+6814<-ksqgelctx()+829<-ktuGetTxForXid()+190<-ktcwit1()+526
<-kdddgb()+9636<-kddlkr()+284<-qerfuProcessFetchedRow()+1019<-__PGOSF308_qerfuLockingRowProcedure()+89
<-qertbFetchByRowID()+2708<-qerfuStart()+590<-selexe0()+3495<-opiexe()+22377<-kpoal8()+2624<-opiodr()+1646
<-ttcpip()+1481<-opitsk()+2166<-opiino()+1246<-opiodr()+1646<-opidrv()+862<-sou2o()+98<-opimai_real()+158
<-opimai()+191<-OracleThreadStart()+724<-0000000076D559CD<-0000000076E8A561
01-04-2018 21:16:06.636
----------------------------------------
SO: 0x00000007606D9B88, type: 4, owner: 0x000000075C68F8B8, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x000000075C68F8B8, name=session, file=ksu.h LINE:12748, pg=0
(session) sid: 68 ser: 20263 trans: 0x0000000755DB9838, creator: 0x000000075C68F8B8
flags: (0x41) USR/- flags_idl: (0x1) BSY/-/-/-/-/-
flags2: (0x40009) -/-/INC
DID: , short-term DID:
txn branch: 0x0000000000000000
edition#: 100 oct: 3, prv: 0, sql: 0x00000007708AA2E8, psql: 0x000000076BDCDED8, user: 0/SYS
ksuxds FALSE at location: 0
service name: SYS$USERS
client details:
O/S info: user: username, term: hostname, ospid: 5968:4960
machine: hostname program: sqlplus.exe
application name: sqlplus.exe, hash value=254292535
Current Wait Stack:
0: waiting for 'enq: TX - row lock contention'
name|mode=0x54580006, usn<<16 | slot=0x130009, sequence=0xb394f
wait_id=10 seq_num=11 snap_id=1
wait times: snap=8 min 15 sec, exc=8 min 15 sec, total=8 min 15 sec
wait times: max=infinite, heur=8 min 15 sec
wait counts: calls=166 os=166
in_wait=1 iflags=0x15a0
Wait State:
fixed_waits=0 flags=0x22 boundary=0x0000000000000000/-1
...
----------------------------------------
SO: 0x0000000778A7FCA8, type: 8, owner: 0x000000075BC6A370, flag: INIT/-/-/0x00 if: 0x1 c: 0x1
proc=0x000000075C68F8B8, name=enqueue, file=ksq1.h LINE:380, pg=0
(enqueue) TX-00130009-000B394F DID: 0001-00A1-0003F59C
lv: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 res_flag: 0x6
req: X, lock_flag: 0x10, lock: 0x0000000778A7FD00, res: 0x0000000760A2BD80
own: 0x00000007606D9B88, sess: 0x00000007606D9B88, proc: 0x000000075C68F8B8, prv: 0x0000000760A2BDA0
---------------------------------------- |
In line 60 you can see that the session is requesting an eXclusive lock for resource res: 0x0000000760A2BD80. When searching for the next appearance of res: 0x0000000760A2BD80, we find a reference to the exclusive enqueue after the last process in a section PSEUDO PROCESS / DETACHED BRANCHES.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | PSEUDO PROCESS for group DEFAULT:
----------------------------------------
SO: 0x000000076068CE68, type: 2, owner: 0x0000000000000000, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x000000076068CE68, name=process, file=ksu.h LINE:12740, pg=0
(process) Oracle pid:0, ser:0, calls cur/top: 0x0000000000000000/0x0000000000000000
flags : (0x20) PSEUDO
flags2: (0x0), flags3: (0x0)
intr error: 0, call error: 0, sess error: 0, txn error 0
intr queue: empty
ksudlp FALSE at location: 0
(post info) last post received: 0 0 0
last post received-location: No post
last process to post me: none
last post sent: 0 0 0
last post sent-location: No post
last process posted by me: none
(latch info) wait_event=0 bits=0x0
Process Group: DEFAULT, pseudo proc: 0x000000076068CE68
O/S info: user: , term: , ospid: (DEAD)
OSD pid info: Windows thread id: 0, image: PSEUDO
PSO child state object changes :
Dump of memory from 0x00000007605E5698 to 0x00000007605E58A0
7605E5690 00000000 00000000 [........]
7605E56A0 00000000 00000000 00000000 00000000 [................]
Repeat 31 times
BEGIN DUMP RESERVED PROCESSES
END DUMP RESERVED PROCESSES
DETACHED BRANCHES:
----------------------------------------
SO: 0x0000000755E7C0F0, type: 58, owner: 0x0000000000000000, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x0000000000000000, name=branch, file=ktccts.h LINE:420, pg=0
(branch) trn = 0x0000000000000000, flg = 0x40, state = 0x00 bno=0 ser=0 evt=0
..
SO: 0x0000000755E2B378, type: 58, owner: 0x0000000755E7C0F0, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x000000077860EB80, name=branch, file=ktccts.h LINE:420, pg=0
(branch) trn = 0x0000000755E01068, flg = 0x41090, state = 0x00 bno=1 ser=10 evt=10
creator = 0x00000007607940E8 uid = 0x42 serial# = 7929 ttl = 0x15180 dtm = 0x5a4db9f5
2PCrole = (nch = 0x0 flg = 0x0) DTP svc = 0x773ffc978
...
SO: 0x0000000755E01068, type: 56, owner: 0x0000000755E2B378, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x000000077860EB80, name=transaction, file=ktccts.h LINE:410, pg=0
(trans) flg = 0x00401e03, flg2 = 0x04080000, flg3 = 0x00000000, prx = 0x0000000000000000, ros = 2147483647, crtses=0x00000007607940E8
...
(enqueue) TX-00130009-000B394F DID: 0001-00E6-000010CD
lv: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 res_flag: 0x6
mode: X, lock_flag: 0x0, lock: 0x0000000755E010E0, res: 0x0000000760A2BD80
own: 0x0000000755E01068 (TXN), sess: 0x0000000000000000, prv: 0x0000000760A2BD90 |
The SEV1 support engineer could not be convinced that the entry DETACHED BRANCHES has nothing to do with the last session listed in the system state dump. I delivered multiple system state dumps and he insisted that the lock was always held by the very last session of the system state dump – what a coincidence. He just scrolled up from the line 46 until the first occurence of “(session)” and was convinced to have found the blocker, not realizing that he overjumped the sections “DETACHED BRANCHES”/”PSEUDO PROCESS for group DEFAULT”.
After some research I found this note:
Solving locking problems in a XA environment ( Doc ID 1248848.1 )
This note explains that with XA (distributed transactions), e.g. DB Links, there can be situations where blocker is not visible. Unfortunately, the symptoms disappeared from the production system before the diagnostic steps from the MOS Note could be tried. Frequently, when there is an issue that remains unsolved, it comes back at a later point and so it was in this case. This time, I was armed with knowledge of the MOS note 1248848.1 and could use the XA rollback script provided there to free up the “session-less” blocking lock.
No entry in DBA_2PC_PENDING but the Query from MOS Note shows Active XA Trans:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | select --+ ORDERED '----------------------------------------'||' Curent Time : '|| substr(to_char(sysdate,' HH24.MI.SS'),1,22) ||' '||'TX start_time: '||t.KTCXBSTM||' '||'FORMATID: '||g.K2GTIFMT ||' '||'GTXID: '||g.K2GTITID_EXT ||' '||'Branch: '||g.K2GTIBID ||' Local_Tran_Id ='||substr(t.KXIDUSN||'.'||t.kXIDSLT||'.'||t.kXIDSQN,1,15)||' '||'KTUXESTA='|| x.KTUXESTA ||' '||'KTUXEDFL='|| x.KTUXECFL ||' Lock_Info: ID1: ' || ((t.kXIDUSN*64*1024)+ t.kXIDSLT) ||' ID2: '|| t.kXIDSQN XA_transaction_INFO from x$k2gte g, x$ktcxb t, x$ktuxe x where g.K2GTDXCB =t.ktcxbxba and x.KTUXEUSN = t.KXIDUSN(+) and x.KTUXESLT = t.kXIDSLT(+) and x.KTUXESQN =t.kXIDSQN(+); "---------------------------------------- Curent Time : 11.35.27 TX start_time: 02/05/18 15:35:17 FORMATID: 131075 GTXID: 312D613331303063613A653165623A35613732336438373A31326335323962 Branch: 613331303063613A653165623A35613732336438373A31326335326166 Local_Tran_Id =25.18.61640 KTUXESTA=ACTIVE KTUXEDFL=NONE Lock_Info: ID1: 1638418 ID2: 61640" "---------------------------------------- Curent Time : 11.35.27 TX start_time: 02/05/18 15:35:17 FORMATID: 131075 GTXID: 312D613331303063613A653165623A35613732336438373A31326335326135 Branch: 613331303063613A653165623A35613732336438373A31326335326165 Local_Tran_Id =16.26.2292874 KTUXESTA=ACTIVE KTUXEDFL=NONE Lock_Info: ID1: 1048602 ID2: 2292874" "---------------------------------------- Curent Time : 11.35.27 TX start_time: 02/05/18 15:35:17 FORMATID: 131075 GTXID: 312D613331303063613A653165623A35613732336438373A31326335326161 Branch: 613331303063613A653165623A35613732336438373A31326335326232 Local_Tran_Id =3.30.3767984 KTUXESTA=ACTIVE KTUXEDFL=NONE Lock_Info: ID1: 196638 ID2: 3767984" |
This output proved that it was CASE 2: No Entry in dba_2pc_pending und Status ACTIVE. Then I could successfully avoid an instance restart and rollback the global transaction to free up the locks.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | set JAVA_HOME=c:\oracle\product\11.2.0.4\dbhome_1\jdk\jre set CLASSPATH=c:\dba\scripts\;c:\oracle\product\11.2.0.4\dbhome_1\jdbc\lib\ojdbc5.jar:%CLASSPATH% C:\DBA\scripts>c:\oracle\product\11.2.0.4\dbhome_1\jdk\jre\bin\java XA_rb jdbc:oracle:thin:@hostname:1521:PROD -ROLLBACK 25 18 61640 ++ URL: jdbc:oracle:thin:@hostname:1521:PROD ++ Rollback of Local_tran_ID : 25.18.61640 ++ got XA resource handle ++ got Connection handle ++ SQL : select g.K2GTIFMT, g.K2GTITID_EXT, g.K2GTIBID, rawtohex( g.K2GTITID_EXT), rawtohex(g.K2GTIBID) from sys.vw_x$k2gte g, sys.vw_x$ktcxb t, sys.vw_x$ktuxe x where g.K2GTDXCB =t.KTCXBXBA and x.KTUXEUSN SLT(+) and x.KTUXESQN =t.KXIDSQN(+) and t.KXIDUSN=25 and t.kXIDSLT=18 and t.kXIDSQN= 61640 ++ Getting XID for Local_Tran_ID: 25.18.61640 + Found global XID: --> ++ Format Id: 131075 ++ Group Id: 312D613331303063613A653165623A35613732336438373A31326335323962 ++ Branch Id: 613331303063613A653165623A35613732336438373A31326335326166 -> Would your really like to continue (yes or no): yes ... doing Rollback ... Rollback done ! |
With Redo Log Mining for the transaction ID, we could get some minor details about the session which initially opened this global transaction.
So whenever you find the strange situation that sessions are blocked on ‘enq: TX – row lock contention’ but there is no blocker in v$session blocking_session column or no entry of a session holding the lock in v$lock, then this MOS Note might be helpful in cleaning up the lock. Sadly, another case where even SEV1 support was no help at all. I have to mention however, that i recently had a SEV1 issue with an excellent and ambitious engineer. So there is still hope…
After a customer asked me for possibilities of super-sizing PGA workareas in version 12c, I took the chance to revisit the topic and perform some tests. Great material has already been posted by late Alex Fatkulin (Hotsos Symposium 2014) and Norbert Debes (Secrets of the Oracle Database, Apress), but I wanted to verify, how the current release is behaving and I found some interesting things.
Quite frequently in database environments, security policies dictate that only personalized logons to Unix / Linux are allowed and that from there, one has to “sudo” to change to the oracle account. While this adds an additional layer of security, it makes administration a little more complicated.
Oracle Enterprise Manager – Cloud Control has a feature, which allows to cope with such a sudo environment. The feature is called “Privilege Delegation”. This post describes how to set it up and for what it can be used.
In order to use privilege delegation, specific sudo rules have to be defined. This rule normally already exists:
1 | mdecker ALL=(root) NOPASSWD:/bin/su - oracle |
In addition to this one, two additional rules are required. If only sudo to “oracle” is required, then only the first line is needed.
1 2 | mdecker ALL=(oracle) SETENV:/u01/app/oracle/cloud/agent/sbin/nmosudo * mdecker ALL=(root) SETENV:/u01/app/oracle/cloud/agent/sbin/nmosudo * |
Go to Setup -> Security -> Privilege Delegation.
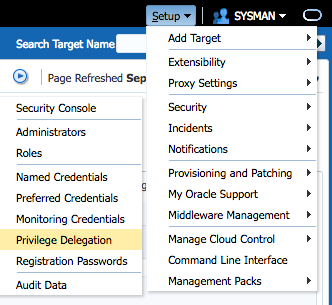
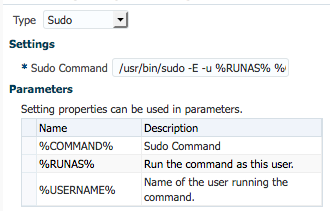
Then you can either set it globally via template or individually for each host. This depends mainly on the path to “sudo” binary in the operating system. Then you choose “sudo” and provide the path to the sudo binary on your operating system (bash$ which sudo). The required parameters are then appended: /usr/bin/sudo -E -u %RUNAS% %COMMAND%
If you are in a team of administrators, then each administrator should have his own account to log on to Cloud Contol and avoid using “sysman” user. For obvious reasons, each administrator has to create his own “named credential” (Setup->Security->Named Credential), because it contains his personalized username and password.
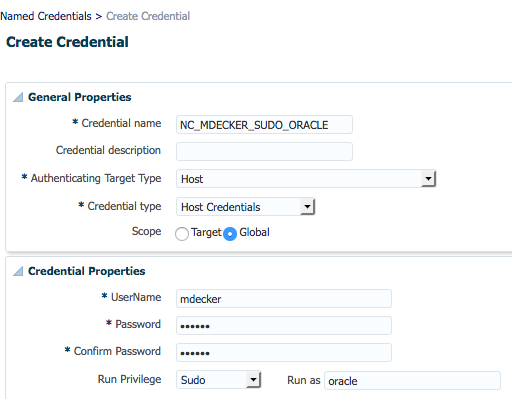
Here you provide your personalized credentials (username/password) and specify that sudo should be used to change to “oracle”.
Go to “Targets” -> “Host” and click “Run Host Command”. Then give the command to run, e.g. “id -a”, and then add a named credential as well as a specific host and click “Run”.
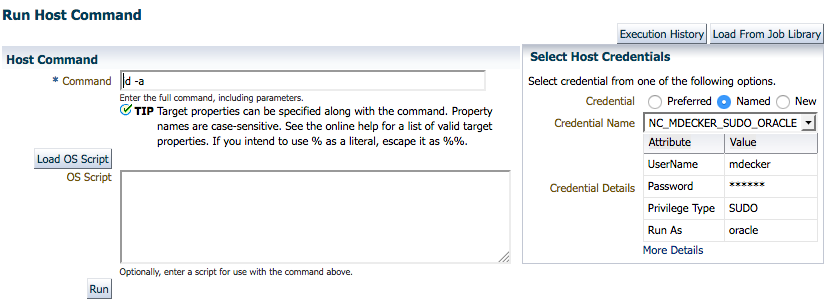
If all is well, then you will get this output showing you the id of user oracle.
![]()
How does this work behind the scenes? The agent java process spawns a process “nmo”. This process was granted SETUID root Privileges by executing $ORACLE_HOME/root.sh at the time of agent deployment. This executable is calling “sudo” to run command “nmosudo” as user oracle with the “payload” command, which the user wanted to execute.
1 2 3 | root 14595 3149 0 14:23 pts/0 00:00:00 /u01/app/oracle/cloud/agent/sbin/nmo root 14598 14595 0 14:23 pts/1 00:00:00 /usr/bin/sudo -p ###AGENT-PDP-PASSWORD-PROMPT### -E -u oracle /u01/app/oracle/cloud/agent/sbin/nmosudo DEFAULT_PLUGIN DEFAULT_FUNCTIONALITY DEFAULT_SUBACTION DEFAULT_ACTION /bin/sh -c id -a oracle 14602 14598 0 14:23 pts/1 00:00:00 sleep 300 |
The linux logfile /var/log/secure will contain this messages. It can be seen that the personal user “mdecker” was running the command “nmosudo” with the payload command “id -a” as attribute.
1 | Sep 13 22:03:59 xxx sudo: mdecker : TTY=pts/2 ; PWD=/u01/app/oracle/cloud/agent/agent_inst/sysman/emd ; USER=oracle ; COMMAND=/u01/app/oracle/cloud/agent/sbin/nmosudo DEFAULT_PLUGIN DEFAULT_FUNCTIONALITY DEFAULT_SUBACTION DEFAULT_ACTION /bin/sh -c id -a |
I recently had to troubleshoot an ORA-4031 issue at a client site. The issue reappeared 3 times within 2 months and only after escalating the SR to SEV1 and being quite persistent for an explanation, the second engineer attempting to solve the issue finally got it right. Being curious, I digged into the trace files again to confirm and understand the issue here. This blog post describes the method to analyze the issue and how to troubleshoot.
ALTER system SET events '4031 trace name HEAPDUMP level 536870914, lifetime 1; name errorstack level 3, lifetime 1'; |
Allocation Request Summary Informaton ===================================== Allocation request for: kglsim object batch ... Heap: 0x6007b278, size: 3896 ****************************************************** HEAP DUMP heap name="sga heap(3,0)" desc=0x6007b278 extent sz=0xfe0 alt=248 het=32767 rec=9 flg=-126 opc=2 ... durations enabled for this heap reserved granules for root 0 (granule size 134217728) Total heap size =2684352800. (2559 MB) Total free space = 38360 Total reserved free space =120837856 (115MB) Permanent space =2563474760 ============================================== TOP 10 MEMORY USES FOR SGA HEAP SUB POOL 1 ---------------------------------------------- "free memory " 6597 MB 71% "gcs resources " 1080 MB 12% "gcs shadows " 748 MB 8% "db_block_hash_buckets " 200 MB 2% "kglsim object batch " 189 MB 2% "kglsim heap " 112 MB 1% "gcs res hash bucket " 64 MB 1% "ges big msg buffers " 54 MB 1% "dbktb: trace buffer " 51 MB 1% "KGLH0 " 48 MB 1% ----------------------------------------- free memory 6597 MB memory alloc. 2747 MB Sub total 9344 MB ============================================== TOP 10 MEMORY USES FOR SGA HEAP SUB POOL 2 ---------------------------------------------- "free memory " 6641 MB 70% "gcs resources " 1080 MB 11% "gcs shadows " 747 MB 8% "db_block_hash_buckets " 512 MB 5% "gcs res hash bucket " 64 MB 1% "kglsim object batch " 59 MB 1% "dbktb: trace buffer " 51 MB 1% "KGLH0 " 44 MB 0% "kglsim heap " 35 MB 0% "ges enqueues " 22 MB 0% ----------------------------------------- free memory 6641 MB memory alloc. 2831 MB Sub total 9472 MB ============================================== TOP 10 MEMORY USES FOR SGA HEAP SUB POOL 3 ---------------------------------------------- "free memory " 6488 MB 71% "gcs resources " 1080 MB 12% "gcs shadows " 747 MB 8% "db_block_hash_buckets " 200 MB 2% "kglsim object batch " 105 MB 1% "gc name table " 72 MB 1% "gcs res hash bucket " 64 MB 1% "kglsim heap " 63 MB 1% "dbktb: trace buffer " 51 MB 1% "KGLH0 " 46 MB 1% ----------------------------------------- free memory 6488 MB memory alloc. 2600 MB Sub total 9088 MB ============================================== TOP 10 MEMORY USES FOR SGA HEAP SUB POOL 4 ---------------------------------------------- "free memory " 6663 MB 70% "gcs resources " 1080 MB 11% "gcs shadows " 749 MB 8% "db_block_hash_buckets " 512 MB 5% "kglsim object batch " 59 MB 1% "dbktb: trace buffer " 51 MB 1% "KGLH0 " 47 MB 0% "kglsim heap " 35 MB 0% "FileOpenBlock " 35 MB 0% "ges enqueues " 22 MB 0% ----------------------------------------- free memory 6663 MB memory alloc. 2809 MB Sub total 9472 MB TOTALS --------------------------------------- Total free memory 26 GB Total memory alloc. 11 GB Grand total 37 GB |
./heapdump_analyzer ./PROD1_ora_27396.trc > heap.txt grep -e "---" -e "Total_size" -e "sga heap(3,0)" heap.txt -- Heapdump Analyzer v1.00 by Tanel Poder ( http://www.tanelpoder.com ) Total_size #Chunks Chunk_size, From_heap, Chunk_type, Alloc_reason ---------- ------- ------------ ----------------- ----------------- ----------------- 114123720 17 6713160 , sga heap(3,0), R-free, 28442152 1 28442152 , sga heap(3,0), perm, perm ... 7485000 1 7485000 , sga heap(3,0), perm, perm 6713080 1 6713080 , sga heap(3,0), R-free, 6712104 1 6712104 , sga heap(3,0), R-perm, perm ... 3028568 1 3028568 , sga heap(3,0), perm, perm ... 8928 4 2232 , sga heap(3,0), perm, perm 7864 1 7864 , sga heap(3,0), perm, perm 5488 2 2744 , sga heap(3,0), perm, perm 3792 1 3792 , sga heap(3,0), free, <<<<<<<<<<<<<< ... |
This shows that the first chunk of chunk_type “free” is of 3792 bytes, but request was for 3896 bytes. The
subpool (3,0) only has R-free (for shared_pool_reserved area) and PERM allocations of bigger size. The subpool (3,0) consists of 20 Extents á (128M Granule size). Each extent has
Researching the issue with “PERM” allocations brought me to:
ORA-4031: unable to allocate 4160 bytes of shared memory (“shared pool”,”unknown object”,”sga heap(4,0)”,”modification “) (Doc ID 1675470.1)
This note also confirms that the classification in 4 durations leads to a weak spot of duration 0 in any subpool for memory allocations due to high PERM utilization. The note mentions patch 8857940, which was also finally recommended by the support engineer.
HEAP DUMP heap name="sga heap(1,0)" desc=0x600680e8 Total heap size =2818570440 Total free space = 28008 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Total reserved free space =127549960 HEAP DUMP heap name="sga heap(1,1)" desc=0x60069940 Total heap size =805305840 Total free space =632590232 Total reserved free space = 40243520 HEAP DUMP heap name="sga heap(1,2)" desc=0x6006b198 Total heap size =1879046960 Total free space =1734275840 Total reserved free space = 93975928 HEAP DUMP heap name="sga heap(1,3)" desc=0x6006c9f0 Total heap size =4294964480 Total free space =4072007248 Total reserved free space =214821040 HEAP DUMP heap name="sga heap(2,0)" desc=0x600719b0 Total heap size =2952788080 Total free space = 19144 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Total reserved free space =147689440 HEAP DUMP heap name="sga heap(2,1)" desc=0x60073208 Total heap size =671088200 Total free space =524561448 Total reserved free space = 33565720 HEAP DUMP heap name="sga heap(2,2)" desc=0x60074a60 Total heap size =1879046960 Total free space =1738701544 Total reserved free space = 93984160 HEAP DUMP heap name="sga heap(2,3)" desc=0x600762b8 Total heap size =4429182120 Total free space =4202264536 Total reserved free space =221534200 HEAP DUMP heap name="sga heap(3,0)" desc=0x6007b278 Total heap size =2684352800 Total free space = 38360 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Total reserved free space =120837856 HEAP DUMP heap name="sga heap(3,1)" desc=0x6007cad0 Total heap size =671088200 Total free space =526361840 Total reserved free space = 33565720 HEAP DUMP heap name="sga heap(3,2)" desc=0x6007e328 Total heap size =1879046960 Total free space =1736230384 Total reserved free space = 93977784 HEAP DUMP heap name="sga heap(3,3)" desc=0x6007fb80 Total heap size =4294964480 Total free space =4076323080 Total reserved free space =214821040 HEAP DUMP heap name="sga heap(4,0)" desc=0x60084b40 Total heap size =2952788080 Total free space = 8536 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Total reserved free space =140977632 HEAP DUMP heap name="sga heap(4,2)" desc=0x60087bf0 Total heap size =1879046960 Total free space =1735347144 Total reserved free space = 93984160 HEAP DUMP heap name="sga heap(4,3)" desc=0x60089448 Total heap size =4429182120 Total free space =4198496144 Total reserved free space =221534200 |
For reference, these are the relevant parameters. Please note that all of these are set to default, except _kghdsidx_count which was reduced from 4 earlier and _ksmg_granule_size which was reduced to 128M.
NAME VALUE ---------------------------------------- -------------------- __shared_pool_size 38923141120 _dm_max_shared_pool_pct 1 _enable_shared_pool_durations TRUE _io_shared_pool_size 4194304 _kghdsidx_count 4 _ksmg_granule_size 134217728 _memory_imm_mode_without_autosga TRUE _shared_pool_max_size 0 _shared_pool_minsize_on FALSE _shared_pool_reserved_min_alloc 4400 _shared_pool_reserved_pct 5 shared_pool_reserved_size 1946157056 shared_pool_size 38654705664 |
Thanks to Tanel, Riyaj and Hatem Mahmoud
